
Ah, the circle of life—it moves us all… even our electronics.
When a new device launches, it’s a celebration. Production lines hum. Budgets flow like champagne. And all the focus is on getting those fresh products out the door—not on future repairs.
But every device grows older.
Parts wear down. Repairs pile up. And sure enough, just as service demand peaks, production winds down. The factory lines shut off and shift to a new, flashier model that takes center stage.
Service takes a back seat. Support teams reassign. Inventory dries up.
The customers who bought the original device?
Still here. Still waiting. Still needing parts.
But the supply chain that they depended on has already packed up and left the building.
Now you’re stuck chasing simple replacement parts that no one wants to make.
The original manufacturers can’t justify spinning up a production line for a handful of parts.
You don’t need ten thousand of something when a thousand would do.
So what’s the choice?
Overbuy and bury your margin in excess inventory?
Underbuy and risk coming up short when your customers need you most?
That’s the timing trap.
It’s quiet, predictable and built into nearly every supply chain that wasn’t designed to handle second-life support. At first, it looks manageable—a delay here, a stockout there. But soon, the cracks widen. Lead times stretch. Service levels crash. Recovery turns reactive, expensive, desperate.![]()
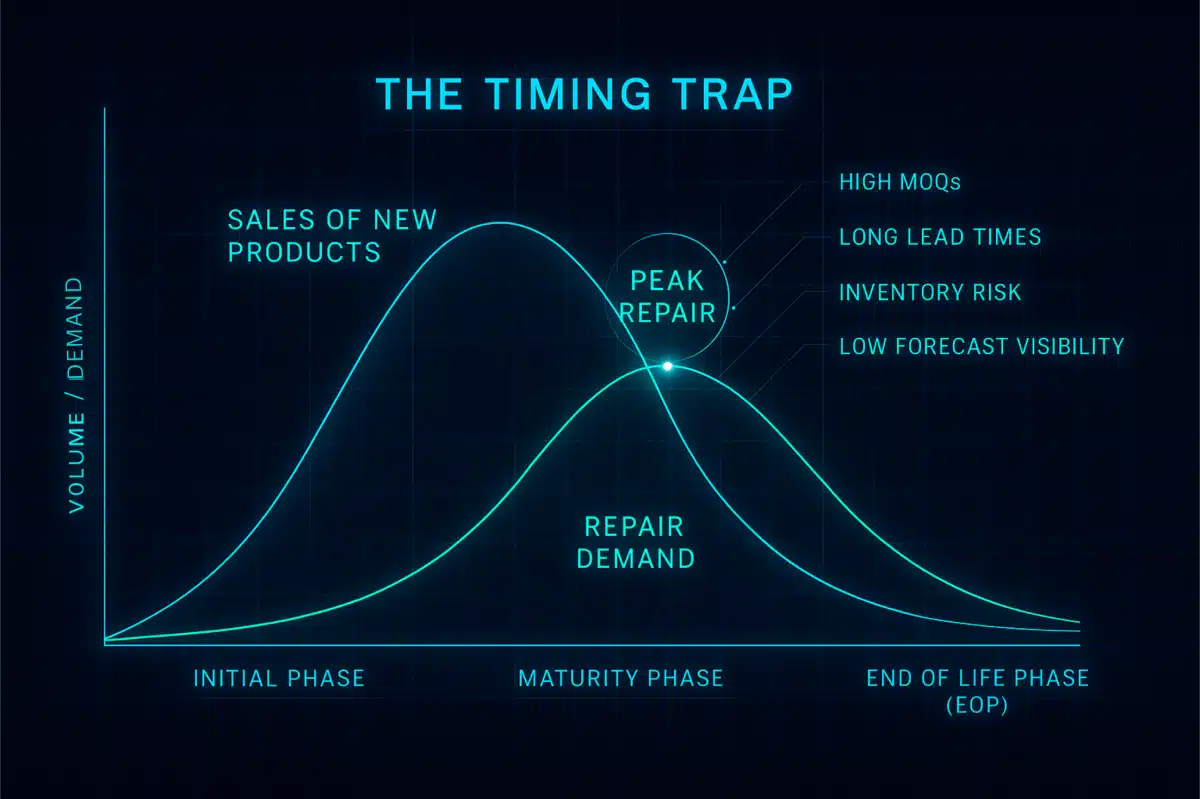
And we’ve seen exactly what happens when there’s no system in place to stop it.
(The collapse is predictable. The fix? We’ll get there.)
The $60M inventory graveyard
One of our clients brought us in after things had already fallen apart.
Edward Zhao, Reconext’s sourcing manager, remembers walking into their repair operation for the first time.
“There was no planning structure,” he recalls. “Just shelves full of aging parts… $60 million worth of inventory, sitting still.”
Every morning followed the same ritual: parts-hold reports at dawn, crisis calls by 8AM and escalation chains looping through the same three spreadsheets. (None of which had the right ETA.)
ODMs blamed upstream suppliers.
Service teams pointed to tickets weeks overdue.
OEM leaders wanted answers the system wasn’t built to deliver.
Level-fill rates were stuck at 76 to 77%. (The contract required 92%.)
Every missed target carried a price: $400,000 a month in penalties.
And every month, someone had to explain (again) why we were still ordering blind and expediting the wrong parts.
And yet, the most common response was always the same:
Buy more. Place a last-time buy. Cross your fingers and hope demand catches up.
Zhao didn’t buy it.
“I don’t recommend this guy take last-time buys,” he said, flatly. “That’s no strategy at all.”
This was the timing trap in action—one of those predictable failure points that’s inherent to legacy recovery systems.
Working around the timing trap isn’t enough. Bypassing it once and for all requires a new approach to recovery—one built on granular data, machine intelligence and systems-level thinking. We call it the Precision Recovery framework (you can read more about it here).
Let’s zoom in on one of the most critical layers of Precision Recovery—Component-Level Intelligence—and how it sets a new standard for second-life operations.
Rethinking what ‘failed’ really means

Most recovery operations still make decisions the way production lines do: Pass or fail. Reuse or discard. Route it to scrap and hope no one audits the logic.
That might pass in production. In second-life recovery, it buries value. A lot of it.
And once the timing trap closes, that buried value is the difference between staying afloat or bleeding out.
That’s where Component-Level Intelligence breaks from tradition.
Instead of treating defective units as write-offs, our Reconext team treats them as layered opportunities. A failed motherboard might still contain salvageable chips. A scratched housing might be repainted and reused. The key is in looking deeper—at the product and at every individual part inside it.
“We don’t treat parts as black boxes,” Zhao explains. “We evaluate everything—cosmetics, performance, signal behavior. Then we decide what can be repaired, recovered or swapped in as an equivalent.”
The sourcing model expands too.
We pull from OEMs, yes—but also from brokers, distributors, refurb factories and open market suppliers. Every material goes through compliance checks, tested to OEM specs before it’s approved for reuse.
“We test functioning, cosmetics, everything,” Zhao says. “We use OEM test criteria to qualify open market inventory.”
When original components are no longer available—especially at end-of-production—Reconext doesn’t stall. Instead, our engineering team builds substitution matrices: mappings that connect legacy parts to compatible replacements.
Sometimes that means swapping in a newer generation. Sometimes it means a better version at a lower cost.
“Take hard drives,” Zhao says. “A 500GB drive today might be hard to get and expensive,” he says. “But a 2TB version costs less and ships right away. With the right validation, we can use that instead.”
This kind of substitution mapping gives the system more flexibility, responsiveness and less reliance on disappearing OEM stock. The result: a system that keeps parts moving without flooding shelves or starving repairs.
And it’s all made possible by a different kind of visibility—one built at the component level.
Now comes the part most teams try to avoid—the planning system itself. (If 12 variables makes your skin crawl, maybe grab a snack first.)
Planning with precision––not panic
Planning tools built for production don’t hold up in recovery. The Precision Recovery framework demanded something more adaptive—so we designed for it.
For most companies, repair parts planning runs on a small set of basic inputs—maybe a dozen variables—if that. But when Reconext engineers built our optimization engine, the goal wasn’t to simplify the math. It was to reflect reality.
And reality is messy.
Our optimization engine tracks over 200 planning variables—each mapped to a specific part of the recovery picture. We track repair yield by commodity, part-level failure curves, inventory by hub, region and factory. We account for substitutions. We track lead times from our suppliers AND from their suppliers.
(Yes, we’ve had to map the failure rates of suppliers’ suppliers. You don’t forget the time a five-cent capacitor delayed 10,000 units.)
Here’s what that precision looks like:
- Each of those parameters is assigned an owner—someone who understands it, tracks it and explains it when things shift. When a yield rate drops or inventory misses the mark, the team knows why it happened and what to do next.
- This structure eliminates one of the most persistent issues in second-life operations: blame without accountability. When the system breaks, no one wants to own the break. This model doesn’t allow that. If something changes, it gets traced, owned and addressed (with data) before it snowballs.
- Even basic metrics like “repair yield” aren’t treated as single numbers. The system breaks them down by part type, age, region, and in some cases, manufacturing batch. That kind of granularity is what makes the entire supply system adaptive.
And that visibility extends to our supplier network.
Because when suppliers know we’re working with six-month demand clarity, they step up. They build around our forecast. They collaborate instead of hedge.
“That’s when the relationship changes,” Zhao says. “Now, you’re steering the system.”
Planning gave us the foresight to stay ahead of gaps, but no amount of forecasting can help if repair itself is constrained. This is where most recovery models tap out. That’s why we built a system that can actually hold up when everything gets weird.
Taking control of the repair layer
In production environments, small failures often come with oversized costs.
OEMs typically don’t sell components individually. They bundle. And those bundles come with MOQs that make no sense for service.
“If you lose a key, you’re buying the whole assembly,” Zhao says. “Margins disappear quickly.”
It gets worse with cosmetic variation. Consumer devices often ship in small-run colorways—red, blue, pink. When replacement parts are needed, OEMs quote MOQs in the thousands, even if the install base is in the hundreds.
We built around it.
That meant designing an adaptive repair ecosystem—one that could respond to fragmented volume, nonstandard needs and unpredictable demand.
We invested in:
- Local repainting and refurbishment for cosmetic parts
- Targeted part recovery from trusted partners and open market suppliers
- In-house repair capabilities for the stuff OEMs won’t touch unless it’s still under warranty (or you’re really loud)
RMA takeover programs because waiting six weeks for a motherboard is a great way to lose a customer

The result? Repairs that used to take weeks were moving in under 48 hours. No escalations, no freight charges, no drama.
“North American operations don’t always see the value in this kind of work,” Zhao says. “But when the supply is fragmented, it’s the only way to stay ahead.”
We didn’t build this alone.
It required supplier relationships grounded in planning, not price. With six-month forecasts in hand, we gave partners the confidence to invest, expanding capabilities around our ecosystem rather than waiting to react.
“The real magic happens when you stop treating the reverse supply chain as episodic,” Shahriyar Rahmati, Reconext CEO says, “and start designing it as a continuous system. When our repair data feeds back into our customers’ design cycle, that’s when circularity becomes real.”
What starts as sourcing evolves into system-building scaffolding. The more clarity we provide, the more capability they develop around the ecosystem itself.
And when quality inventory isn’t available? We qualify it ourselves.
Open market components are tested against OEM specifications—for cosmetics, function and electrical behavior—through the same compliance standards we use for direct-sourced parts.
Adaptive repair lets us respond in real time, salvaging what works instead of tossing what doesn’t. We don’t wait for OEM constraints to dictate outcomes. We decide what’s viable, validate it internally and move.
That’s what autonomy looks like.
How the model changed the math
Once the ecosystem was in place—component-level sourcing, repair autonomy and predictive planning—the changes were immediate.
Nine months in, our client’s inventory dropped from $60 million to $21 million. Fill rates hit 97%. The shelves were clearing and the penalties were replaced with incentives!

Our optimization system made daily sourcing decisions based on cost, lead time and availability—adjusted continuously across regions and partners. (And if something shifts mid-week, it gets recalculated. No PowerPoint required.)
The recovery curve bent fast. What once took weeks started moving in days. Instead of replacing full assemblies, we validated parts individually. Motherboards, top covers, keyboard components—previously discarded—were now repaired, refurbished or substituted based on real-time availability.
That shift alone cut repair part costs by more than 40%—compared to what they were paying their ODM to over-package and overcharge for assemblies they didn’t need.
Eventually, they asked us to present our system as their global best practice.
The logic held up—visible in better yields, steadier inventory and fewer angry calls from service.
Designing a system that doesn’t break
Production plans around build schedules. Second-life deals with parts failing at random and customers already on the line. The economics change, the risks change and so do the rules.
But the mistake is treating that complexity as unchangeable. Like it’s just the cost of doing business after end-of-production.
It isn’t.
The breakdowns we’ve seen—spiked lead times, inflated MOQs, ballooning inventory—are generated by the system itself. The tools, the planning models, the supplier terms—they produce the chaos.
The Precision Recovery framework was built to change that, starting at the component level, where the real failure patterns begin.
That’s the shift.
When repair intelligence shapes design, circularity becomes real.
PUT THIS SYSTEM TO WORK FOR YOU
If your supply chain is reacting to gaps, we can help you start designing around them. Let’s talk about where this model could cut lead times, skip last-time buys or keep your team off another 8AM crisis call.
Read more about the Precision Recovery approach here, or reach out if you want to know what first steps look like.


